目次
はじめに
科学技術計算講座の第7回目のシリーズを開催したいと思います。
今回の講座のテーマは「PythonでWebブラウザの解析作業を自動化」です。
流体解析を始めとするCAE解析において、計算設定や計算実行、結果処理など様々な処理が必要になります。ソフトウェアでのこれらの処理には時間と手間がかかるものです。同じ計算モデルで、境界条件を少し変えて複数の計算を行ったり、形状を少しずつ変えて解析実行をする場合、同じ処理を何度も行うのは、とても面倒です。
そこで、必要最低限の入力で後は、計算機が自動で処理を実行してくれれば、人間の作業時間はとても短くなり、できた時間を他の仕事に当てたり、早く帰宅して自分の時間に使うことができます。
商用のCAEソフトの多くは、マクロ機能を持っているので、決まりきった定形作業はマクロ化しておいて、自動化することができます。Linuxサーバーなどで計算実行する場合は、スクリプトを組んで、入力条件を変えながら計算を自動実行させることも可能です。夕方帰宅する前に計算を仕掛けておいて、夜中の間コンピュータに自動で計算実行させて、翌日結果を見るということもよくやります。Windowsでも、バッチ処理ができるので、同じように自動化することもできます。
しかし、Webブラウザ上で動くアプリケーションの場合はどうすればよいでしょうか。例えば、このサイトの計算ツールもWebアプリケーションの一種です。他にも、企業であれば、解析ソフトや計算ツールがシステム化されていて、Webブラウザ上で設定して計算実行するというような形になっている所も多いと思います。
そこで、今回はそのようなWebブラウザ上のアプリケーションをPythonを使って自動実行させる方法について学んで行くことにします。
Pythonの準備
この講座ではPythonを使います。Pythonはこれまでの講座でも使ってきました。Anacondaの環境でPythonを使うようにしていますので、下記の記事を参考にして、Python環境を作っておいてください。

Seleniumとは
この講座ではPythonからWebブラウザに表示されているページやアプリケーションを操作していきます。その操作の手順をPythonでプログラミングします。
ここでは、PythonからWebアプリケーションを操作するためのフレームワークとして、「Selenium」というツールを使います。
Seleniumは、もともとWebアプリケーションのテストを自動化する目的で作られました。ボタンをクリックしたり、テキストボックスに文字を入力したり、ページ上の文字や値を取得したりといった、Webブラウザ上の様々な操作を実行することができます。
なお、SeleniumはPythonだけでなく、様々な言語に対応しています。
Seleniumのインストール
では、Seleniumをインストールしましょう。Anacondaのプロンプトで以下のコマンドでSeleniumをインストールできます。
pip install seleniumChromeドライバのインストール
この講座では、WebブラウザはGoogle Chromeを使います。Seleniumを使ってWebブラウザを操作するためには、そのブラウザのドライバWebDriverというものが必要になります。
Chromeのドライバは、以下の公式サイトからダウンロードできます。
ChromeDriver - WebDriver for Chrome (google.com)
このサイトのDownloadsの中から、自分が使用しているChromeのバージョンにあったものをダウンロードします。解凍すると、chromedriver.exeというファイルがあります。
このchromedriver.exeをこれから作るPythonプログラムファイルと同じフォルダに置いておきます。
なお、Microsoft Edgeでも同様にドライバが用意されています。ドライバを置き換えれば、Pythonプログラムの内容は基本的に同じです。
Microsoft Edge ドライバー - Microsoft Edge Developer
Web操作プログラミングをはじめよう
では、Web操作のプログラミングをはじめてみましょう。最初はとても簡単ですが、当サイトにアクセスして、ページを表示してみます。
Pythonプログラム
早速ですが、Pythonプログラムを載せておきます。
from selenium import webdriver
import time
# webdriver
driver = webdriver.Chrome("./chromedriver.exe")
driver.get("https://cattech-lab.com/science-tools/")
# wait
time.sleep(3)
# close driver
driver.quit()以下、プログラムの内容を説明していきます。
from selenium import webdriver
import time最初の行は、seleniumを使うためのモジュールをインポートしています。次のtimeは、実行の処理待ちを与えるために必要なモジュールをインポートしています。
# webdriver
driver = webdriver.Chrome("./chromedriver.exe")
driver.get("https://cattech-lab.com/science-tools/") 次にwebdriver.ChromeでChromeドライバを指定します。ここでは、Pythonファイルと同じフォルダに置いているものとして、相対パスで指定しています。
ドライバに対して、getでアクセスするページのURLを指定します。これで、ブラウザが起動され、そのページが表示されます。
# wait
time.sleep(3)
# close driver
driver.quit()time.sleep(3)は、処理を3秒間待つという命令です。sleepで指定した秒数だけ、処理を停止します。
最後の、quitはドライバを閉じます。つまり、ページが表示されて3秒後に閉じることになります。
プログラムの実行
プログラムを実行してみてください。ブラウザが起動され、ページが表示されて3秒後にブラウザが閉じると思います。
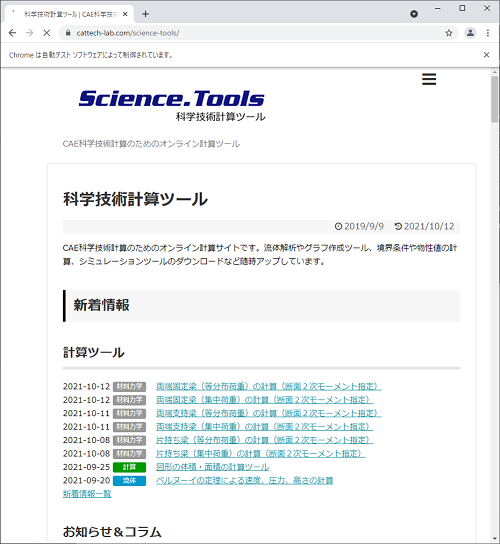
ブラウザの上部には「Chromeは自動テストソフトウェアによって制御されています。」と出力されています。
今回は、ページを表示して閉じただけで、特に何も操作しませんでした。でもまずは第一歩ということで、どのような感じでPythonとSeleniumでWebブラウザにアクセスするか理解できたかと思います。
Web操作自動化の注意
最後にWeb操作を自動化するうえでの注意事項について述べておきます。Web操作を自動化すると、わずらわしい繰り返し作業が自動で行われるのでよいのですが、逆を言えば自動で何でもできるロボットを作ることができてしまいます。
いわゆるボットやクローラといったロボットが、Webネットワーク上では大量に様々な操作を行っています。中には悪意を持って、サイト上に侵入したり、大量のリクエストを送りサーバーをダウンさせたりするものもあります。また、悪意がなくても、プログラムのバグなどから知らず知らずのうちにサーバーに負荷をかけたりする恐れもあります。故意であるかないかに関わらず、システムに障害を及ぼすような場合は、法的措置が取られることもあるため、細心の注意が必要です。
また、Webサイトやアプリケーションによっては、利用規約によりクローリングやスクレイピング(Webサイトから様々な情報を取得するソフトウェア技術)を禁止している場合もあります。自動化ツールでのログインを禁止しているサイトもあります。このような場合も発覚すれば何らかの措置がとられる可能性があります。
いずれにしても、外部サイトだけでなく自社サイトにおいても、サーバーに負荷をかけていないか、利用規約に反していないかなど注意を払っておく必要があります。
まとめ
今回はSeleniumを使ってPythonでWebブラウザを操作する最初の一歩についてお話しました。
次回は、実際にブラウザ上に値を入力して、計算結果を取得してみたいと思います。